

WIPL-D GPU Solver is an add-on tool that exploits high computation power of nVIDIA CUDA™-enabled GPUs to significantly decrease EM simulation time. Acceleration by an order of magnitude can be achieved when compared to a CPU multi-threaded solution.
The sophisticated parallelization algorithm results in a highly efficient utilization of an arbitrary number of GPUs. Supported GPUs are nVIDIA’s CUDA-enabled GPUs (GeForce, Tesla or Quadro series) with compute capability 2.0 and higher.
The greatest speed-up is achieved in the most time demanding part of an EM analysis, the matrix inversion. Matrix fill‑in and near‑field calculation are also GPU accelerated. Usage of the GPU solver for near‑field calculation is recommended. On the other hand, matrix fill‑in is often faster if multi‑core CPU is used.
GPU acceleration versus number of unknown coefficients is given for two hardware configurations: a desktop PC equipped with 1 GPU, and a server equipped with 4 GPUs. In all simulations used to produce the following figures CPU fill-in is used. The graphs below illustrate the reduction of total simulation time, when GPU inversion replaces CPU inversion.
The desktop machine configuration is as follows: Intel® Core™ i7-7700 @ 3.60 GHz, 64 GB of RAM, one nVIDIA GeForce GTX 1080 GPU. GPU acceleration increases with increasing number of unknown coefficients. For 80,000 unknowns, acceleration is ~10 times. Number of unknowns where the GPU solution becomes faster than the CPU solution is ~5,500. Nevertheless, significant acceleration is not noticeable for less than 10,000 unknowns.
As an illustration, simulation time (when CPU fill-in and GPU inversion are used) for a problem with 10,000 unknowns is 5 seconds, and for a problem with 80,000 unknowns it is 6.8 min.

GPU acceleration @ desktop PC with 1 GPU
The server configuration is as follows: Intel Xeon CPU E5-2660 v2 @2.2 GHz (2 processors), 256 GB of RAM, four nVIDIA GeForce GTX 1080 Ti GPUs and 7 SATA HDDs configured in RAID-0 configuration. Acceleration increases with increase of the number of unknowns.
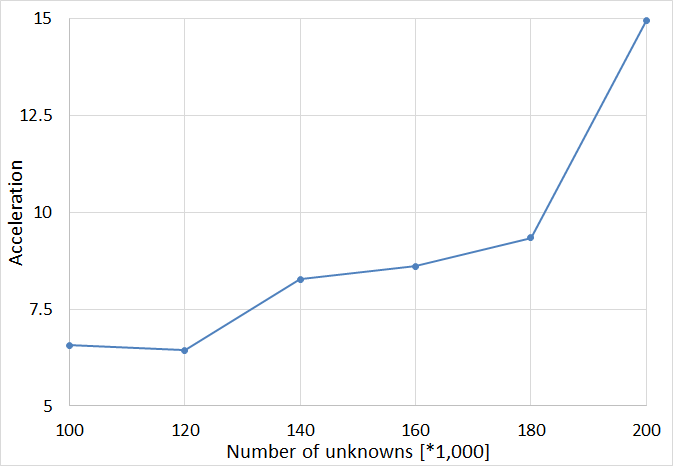
GPU acceleration @ server with 4 GPUs
An abrupt change in acceleration is achieved when the number of unknowns increases from 180,000 to 200,000. The reason for such behavior is the switching of the matrix inversion to out-of-core. In the case of GPU Solver HDDs I/O operations are performed in parallel with GPU calculations, which provides additional acceleration when compared to CPU calculations.
A problem with 100,000 unknowns is solved in 6.4 min, while the simulation time for 200,000 unknowns is 46.5 min.
In case you need more info on GPU configurations and ways to use the GPU speed-up on your computer, feel free to contact us.
Some of the application areas where GPU solver has been successfully exploited are shown below in a form of a technical paper or a publication:
- Application note – GPU Accelerated MoM Matrix Inversion
- Application note – Coaxial Fed Dipole Mounted on F-16 at 1.9 GHz
- Application note – Monostatic RCS of Fighter Aircraft
- IEEE paper – B. Lj. Mrdakovic, M. M. Kostic, D. I. Olcan and B. M. Kolundzija, “Acceleration of in-core LU-decomposition of dense MoM matrix by parallel usage of multiple GPUs,” 2017 IEEE International Conference on Microwaves, Antennas, Communications and Electronic Systems (COMCAS), Tel-Aviv, 2017, pp. 1-4.
- IEEE paper – D. P. Zoric, D. I. Olcan and B. M. Kolundzija, “Solving electrically large EM problems by using out-of-core solver accelerated with multiple graphical processing units,” 2011 IEEE International Symposium on Antennas and Propagation (APSURSI), Spokane, WA, 2011, pp. 1-4.